“Finding a better mousetrap” is a saying that is synonymous with businesses that are on the lookout for an easy solution to a common problem.
One such solution has been developed by iText Group NV, a global leader in PDF software.
Their focus isn’t on providing an easier way to catch mice, but on improving the everyday life of people who work in the area of recording and processing documents.
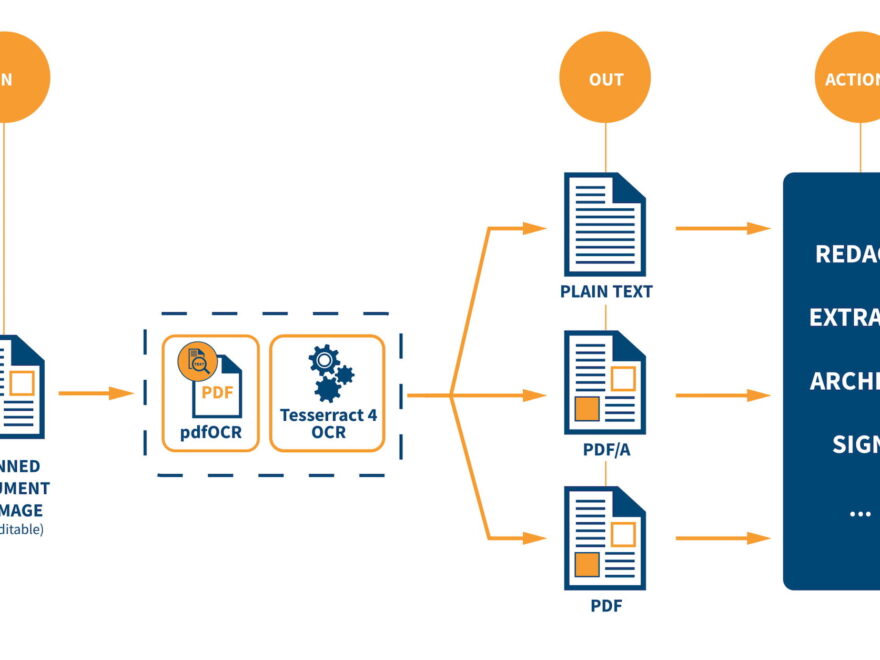
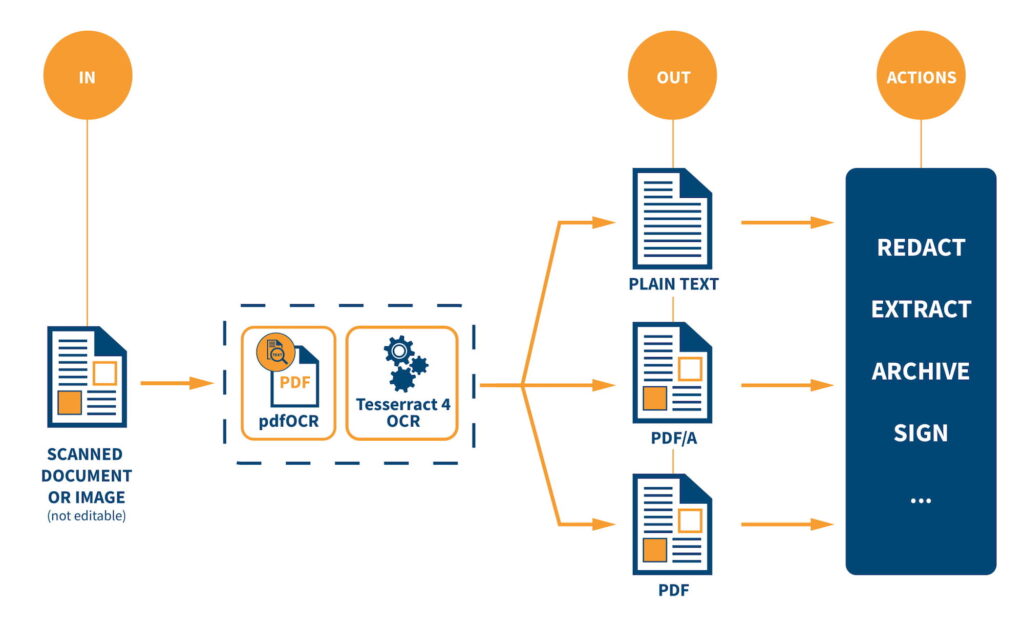
Their new open-source product, iText pdfOCR, allows for scanned documents to have the text within them recognised and processed into an editable PDF.
It does this by engaging with Optical Character Recognition, which is a function that allows the text within scanned documents and photographs to be converted into a searchable PDF format.
Yeonsu Kim, CEO at iText Group NV, discussed its potential, stating:“With COVID-19 urging companies to accelerate their digital transformation projects, organizations are forced to explore new ways of accessing and managing their data – existing and new.”
This tool will be an asset to those working in the areas of archiving and data-entry, however it is not where it’s uses end. The iText pdfOCR also uses existing technology to translate the documents being scanned into different languages.
The CEO added: “Being a leader in the digital documents space, we’re pleased to be at the forefront of this new era.
“As such, I am very proud to announce the latest addition to our PDF library for today’s new world: thanks to the OCR capabilities of iText pdfOCR many new opportunities will open up for users and enterprises that want to maximize their data potential.”

Jenny has been reporting on small business issues since 2001 where she held a number of freelance positions across the leading SME publications in the UK. Specialist subjects included SME financing and tax.